How GPT-image-2 Microsoft Foundry Changes the Math on Enterprise Visual AI
 Sudhir K Srivastava
Sudhir K SrivastavaLet's talk
Table of Contents:
- GPT-image-2 Microsoft Foundry: What You Should Know First
- The Capability Gap Most Teams Are Solving for Last
- Where Enterprise AI Image Adoption Stalls at the Same Point
- Flexsin’s AI Image Readiness Framework for Enterprise Foundry Adoption
- Flexsin in Practice
- What Production-Grade Results Actually Look Like in GPT-image-2 Microsoft Foundry
- GPT-image-2 Microsoft Foundry: When Things Get Challenging
- People Also Ask
- Ready to evaluate GPT-image-2 for your enterprise AI image generation pipeline?
- Common Questions Answered
GPT-image-2 is now generally available in Microsoft Foundry – and it’s not a marginal upgrade. An AI image generation knowledge cutoff 2025, 4K resolution support, multilingual rendering, and an intelligent token-routing layer redefine what enterprise teams can ship from a single image generation call. It is whether your architecture is ready to use it.
Most enterprise AI image generation visual content operations still run on a fragmented stack: separate tools for format, resolution, localization, and approval. A mid-market retail brand managing campaigns across six geographies might have three agencies and two internal tools just to keep asset dimensions consistent. That is not a content problem. It is an architecture problem of generative image pipeline.
Understanding what GPT-image-2 4K resolution in Microsoft Foundry actually changes – and where it doesn’t – is the decision an engineering or AI strategy lead needs to make now, before committing pipeline redesign effort to the wrong assumptions.
GPT-image-2 Microsoft Foundry: What You Should Know First:
- GPT-image-2 is live on Microsoft Foundry today, with a December 2025 knowledge cutoff that makes contextual outputs materially more relevant.
- 4K resolution support and token-based routing are the two architectural features with the greatest impact on production workflow design.
- Multilingual text rendering – including Japanese, Korean, Chinese, Hindi, and Bengali – enables localised asset production without post-production text overlays.
- GPT-image-2 pricing per token is: $8 per 1M input image tokens and $30 per 1M output tokens at Standard Global tier.
- Microsoft Foundry image model’s safety layer combines OpenAI’s image moderation with Azure AI Content Safety classifiers – governance is built in, not bolted on.
- The AI image generator market is on a trajectory to $30 billion by 2033 (SkyQuest, 2025). Teams that build production fluency now will hold a structural advantage over those that treat this as a late-cycle adoption.
The Capability Gap Most Teams Are Solving for Last
Here’s what gets missed in most AI image generation evaluations: resolution and language support are not end-user features – they are infrastructure constraints. A model that cannot render 4K output does not give designers more options; it gives developers a hard ceiling on what downstream use cases are even possible. Most enterprise AI image generation teams discover this ceiling only after committing a pipeline to a model that cannot support their highest-volume format.
GPT-image-2 Microsoft Foundry moves that ceiling significantly. Total pixel budget extends to 8,294,400 pixels – supporting 4K and custom dimension outputs where each dimension must be a multiple of 16. The system also enforces a floor of 655,360 pixels, which means production-grade AI image generation requests will not silently produce unusable thumbnails when resolution parameters are ambiguous. That floor is an underrated governance feature for quality-controlled production in enterprise generative AI visual pipelines.
The straightforward answer is that most enterprise image generation failures are not model failures – they are dimension specification failures. Engineers set parameters once, at implementation, and the model runs those parameters against every prompt regardless of whether the output format has changed. GPT-image-2’s intelligent image routing AI layer addresses this automatically, drawing from two distinct modes: a legacy size-tier mode for teams transitioning from existing workflows, and a token bucket mode for AI image generation enterprise workflow, offering six size configurations that trade off quality and efficiency granularly for GPT-image-2 vs GPT-image-1.

Where Enterprise AI Image Adoption Stalls at the Same Point
Across industries, the same sequence repeats for AI visual content production at scale. An enterprise AI image generation team runs a successful proof of concept – typically in marketing or e-commerce – then attempts to scale the model into a production asset pipeline. That’s where it breaks. The Microsoft Foundry image model they tested was not designed for the resolution, language, or governance requirements of real-world production volumes.
The Three Stall Points:
The first is resolution mismatch. A model producing 1024×1024 outputs works for web thumbnails; it fails for print-ready campaign assets or high-density display advertising. Teams discover this at the production handover stage, not during evaluation of visual AI infrastructure.
The second is localization friction in AI image generation for retail marketing. Rendering text directly in images requires a model with genuine multilingual understanding. Most image generation models treat non-Latin scripts as decorative elements. GPT-image-2’s expanded support for Japanese, Korean, Chinese, Hindi, and Bengali signals a different architectural philosophy: text in the image is part of the generation, not a workaround applied after.
The third is governance latency. Enterprise deployments require content safety at the API layer, not as a separate review step. Microsoft’s approach layers OpenAI’s native moderation with Azure AI Content Safety classifiers – safety decisions happen at generation time, not after.
Flexsin’s AI Image Readiness Framework for Enterprise Foundry Adoption
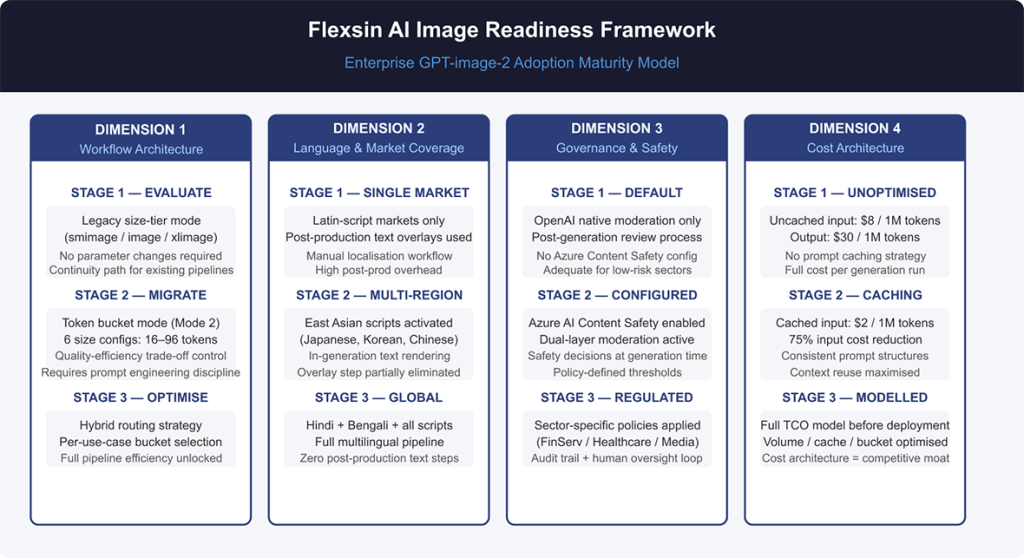
Not every enterprise is ready to move GPT-image-2 into production immediately. The capabilities are real, but the deployment complexity is also real. Flexsin’s AI Image Readiness Framework evaluates enterprise adoption across four dimensions.
Dimension 1 – Workflow Architecture Readiness
Routing Mode 1 (legacy size tiers: smimage, image, xlimage) provides continuity for teams with existing parameter conventions. Mode 2 (six token buckets: 16, 24, 36, 48, 64, 96) offers finer efficiency control but requires prompt engineering discipline to avoid inconsistent outputs across bucket boundaries. Most teams should start in Mode 1 and migrate selectively, using Azure OpenAI visual stack.
Dimension 2 – Language and Market Coverage
If production requirements for multilingual AI image generation include markets where Hindi, Bengali, or East Asian languages appear in final imagery, GPT-image-2 Microsoft Foundry’s multilingual text rendering eliminates an entire post-production step – a workflow compression opportunity, not just a model upgrade.
Dimension 3 – Governance and Safety Configuration
OpenAI image generation Azure Content Safety is a configuration layer, not a mandatory toggle. Teams should define their content safety policy before production deployment, particularly in sectors with regulatory exposure: financial services, healthcare communications, children’s media.
Dimension 4 – Cost Architecture
Cached input tokens are priced at $2 per 1M – which means teams running repetitive prompt structures with consistent context can compress costs materially. For a retail team generating 10,000 product images per month, the difference between cached and uncached input, and enterprise image resolution control is worth modelling before any deployment commitment.
Flexsin in Practice
At Flexsin, our generative AI services and AI application development practice has seen a consistent pattern across enterprise clients: the teams that extract the most value from image generation models treat model selection as an infrastructure decision, not a creative one. Evaluating token routing architecture, governance layers, and resolution ceilings before the first prompt is written separates successful deployments from expensive restarts. The right model can enable a pipeline specification you could not previously justify building.
Working with a mid-size US e-commerce company managing product imagery across eight regional storefronts, Flexsin’s team rebuilt their asset generation pipeline around Azure AI Foundry image model deployment – reducing manual format conversion and text-overlay steps by 60% within the first quarter of deployment. GPT-image-2 Microsoft Foundry’s intelligent image routing AI layer was the specific capability that made automated dimension management viable at that scale. Teams that wait for the production crisis of multimodal AI content generation to trigger model evaluation almost always spend twice the implementation time of those who make the call at the architecture stage.
What Production-Grade Results Actually Look Like in GPT-image-2 Microsoft Foundry
The Microsoft Foundry announcement demonstrates GPT-image-2’s fidelity progression across three model generations using the same base prompt. Each successive model – GPT-image-1, GPT-image-1.5, then GPT-image-2 – produces measurably more detailed and photorealistic output. The incremental edit test is more revealing: adding a branded campaign to existing image elements, then refining specific visual details across three prompt steps. That kind of iterative fidelity – where the model holds prior context and applies targeted changes – is what separates a creative tool from a production tool for responsible AI image deployment.
82% of enterprises with over 1,000 employees currently use generative AI tools in at least one business function, according to McKinsey’s Global Survey on AI. The gap between that adoption breadth and production-depth is where GPT-image-2 in Microsoft Foundry makes its strategic argument: the model is designed for the depth end of that spectrum.
GPT-image-2 Microsoft Foundry: When Things Get Challenging
Token-based pricing rewards prompt engineering discipline, but penalizes teams that haven’t built that discipline yet. A poorly structured prompt generating unnecessary output tokens can consume budget faster than an equivalent per-image pricing model.
Dimension constraints carry edge cases. The 655,360 pixel floor means very small thumbnail requests will be resized up, affecting performance for high-volume thumbnail pipelines. The 8,294,400 pixel ceiling means requests targeting print resolution beyond standard 4K will be automatically resized down – validate output specifications before committing workflows.
The intelligent routing layer is automatic by design. Teams needing deterministic, repeatable dimension outputs for regulated asset workflows may find automatic token-based image routing introduces variance they cannot accommodate. Mode 1 and Mode 2 provide control, but explicit dimension specification remains the safer choice where reproducibility is a hard requirement for responsible AI image deployment.
People Also Ask:
1. What is GPT-image-2 in Microsoft Foundry?
GPT-image-2 is OpenAI’s latest image generation model, now generally available on Microsoft Foundry. It supports 4K resolution, multilingual text rendering, and an intelligent routing layer for enterprise production workflows.
2. How does GPT-image-2 differ from GPT-image-1?
GPT-image-2 adds 4K resolution support, a December 2025 knowledge cutoff, and token-based intelligent routing. It also extends multilingual text rendering to Hindi, Bengali, and East Asian languages.
3. What are the resolution limits for GPT-image-2 Microsoft Foundry?
The model supports a pixel range of 655,360 to 8,294,400 total pixels. Supported resolutions include 4K, 1024×1024, 1536×1024, and 1024×1536, with each dimension a multiple of 16.
4. How is GPT-image-2 priced in Microsoft Foundry?
Pricing is per 1M tokens: $8 for input image tokens, $2 for cached input, and $30 for output tokens. Text input is $5 per 1M tokens, cached at $1.25.

Ready to evaluate GPT-image-2 for your enterprise AI image generation pipeline?
Flexsin’s generative AI services team has deployed Azure AI Foundry image generation workflows for retail, media, and marketing operations across North America and APAC. We can help you assess routing architecture, governance configuration, and cost modelling before you commit to production.
Talk to a Flexsin generative AI specialist today.
Common Questions Answered:
1. Is GPT-image-2 Microsoft Foundry available to all Azure customers?GPT-image-2 is generally available through Microsoft Foundry at ai.azure.com. Standard Global deployment applies to eligible Azure accounts.
2. What languages does GPT-image-2 support for in-image text?The model supports multilingual text rendering including Japanese, Korean, Chinese, Hindi, and Bengali. This covers the major Asian enterprise markets.
3. Can GPT-image-2 edit existing images?Yes, the model supports incremental image editing via sequential prompts. Microsoft’s announcement demonstrates multi-step editing maintaining visual context across prompt iterations.
4. What is the knowledge cutoff for GPT-image-2 Microsoft Foundry?GPT-image-2 has a knowledge cutoff of December 2025. This enables more contextually accurate outputs for recent brand elements, products, and visual references.
5. How does intelligent routing work in GPT-image-2?Routing Mode 1 selects from three legacy size tiers automatically. Mode 2 selects from six token buckets (16-96), enabling finer quality-efficiency optimization per prompt.
6. What safety controls apply to GPT-image-2 on Foundry?The model combines OpenAI’s native image moderation with Azure AI Content Safety classifiers. Human oversight is maintained throughout the generation and review process.
7. Is GPT-image-2 Microsoft Foundry better than DALL-E 3 for enterprise use?GPT-image-2 represents a generational improvement in instruction following, resolution support, and multilingual rendering. Enterprise teams with production pipeline requirements will find it substantially more capable.
8. How does token-based pricing compare to per-image pricing?Token-based pricing rewards prompt efficiency and caching strategies. Cached-token pricing at $2 per 1M reduces costs significantly versus uncached requests at $8 per 1M.
9. Can Flexsin integrate GPT-image-2 into our existing Azure environment?Yes, Flexsin’s AI application development team specialises in Azure AI Foundry image model deployments. We handle architecture design, API integration, safety configuration, and workflow automation.
10. What industries benefit most from GPT-image-2 Microsoft Foundry in enterprise settings?Retail, marketing, media production, and e-commerce benefit most. Any industry requiring high-volume, multilingual, or dimension-specific visual asset production is a strong candidate.
