Before You Scale GenAI, Fix Your Data Management
 Munesh Singh
Munesh SinghTable of Contents:
- Data Management for GenAI Success
- The Five Leverage Points for GenAI Data Governance
- Why the Human-in-the-Loop Is Still Non-Negotiable
- People Also Ask</a
- Build an AI-Ready Data Foundation with Flexsin</a
- Frequently Asked Questions
The models are not the problem. Most enterprise GenAI initiatives stall – or quietly die after proof of concept – because the data underneath them is broken, ungoverned, and invisible. That is the uncomfortable truth that board presentations tend to skip and implementation timelines eventually hit like a wall.
Gartner research shows that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data (Gartner, February 2025). That is not a technology failure. That is a data governance failure. And it is happening inside organizations that have already spent millions on foundation models, cloud compute, and fine-tuning GenAI data pipelines.
This is what makes GenAI for data management both the most misunderstood and most urgent problem in enterprise AI today. You cannot fix it by buying a better model. You fix it by using AI to govern the data that AI depends on.
Data Management for GenAI Success
Traditional data governance was designed around structured data – the clean, labeled rows living inside relational databases. That world had rules. Lineage was traceable. Classification was manageable. Compliance was painful but possible.
GenAI broke that world. It trains on unstructured data – emails, contracts, call transcripts, engineering documentation, customer conversations. According to Informatica’s CDO Insights survey of 600 enterprise data leaders, 42% cited data quality as the single largest obstacle to generative AI implementation, ahead of privacy and AI ethics concerns (Informatica, January 2024).
Here is the deeper problem: the volume of unstructured data that GenAI requires to function well is also the category of data that human data stewardship teams were never equipped to manage at scale. The only viable answer is to deploy AI to govern AI-ready data. Not because it is elegant – because there is no alternative that scales.

The Five Leverage Points for GenAI Data Governance
1. Automated Metadata Management at Scale
Metadata is the nervous system of enterprise AI data governance. Without it, no model knows whether a document is a legal contract, a marketing brief, or a patient record. Historically, creating that metadata was exhaustive manual work – and in most organizations, that work is three to five years behind the growth of the underlying data estate.
GenAI for data management changes the economics entirely. Through large language model-based classification, organizations can automatically generate metadata labels for unstructured assets – specifying source, usage rights, content relationships, regulatory flags, and sensitivity tiers. What previously took a team of analysts weeks can now be run overnight across millions of documents, leveraging the capabilities of GenAI for data management.
2. Data Lineage Automation
Cross-system lineage – knowing exactly where a data element originated, how it was transformed, and where it flows – is non-negotiable in regulated industries and for any organization that needs to explain an AI decision. Historically, capturing lineage required painstaking manual documentation that was outdated the moment a pipeline changed.
GenAI for data management automates lineage through code-parsing techniques and natural language generation, producing initial lineage drafts that governance teams then validate rather than create from scratch. That shift from creation to validation is not a small productivity gain – it is a category shift in how data stewardship AI automation teams operate.
3. Generative AI Data Quality Augmentation
Data quality for AI models is a fundamentally different problem from traditional data quality. It is not enough for data to be accurate and complete. It must also be representative of the problem space, free from the specific biases that cause model drift, and appropriately diverse across the patterns an AI model needs to generalize correctly.
GenAI for data management tools can profile datasets for these AI-specific quality dimensions – automatically flagging gaps in coverage, near-duplicate contamination, and distributional imbalances that traditional data quality tools were never designed to detect. This is the layer where most organizations are completely blind, and where model failures that appear mysterious in production were actually inevitable from the moment training data was selected.
4. Policy Compliance and Data Anonymization
The regulatory surface area for enterprise AI data management is expanding fast – GDPR, the EU AI Act, CCPA, sector-specific requirements in finance and healthcare. GenAI governance frameworks enable automated policy enforcement by classifying data against regulatory taxonomies.
5. AI-Ready Data Certification
Perhaps the most strategically important use case is the concept of AI model data readiness certification – a structured, auditable process by which a dataset is assessed and validated before it enters a training or retrieval pipeline. Industry analysts estimate that AI can automate up to 90% of traditional governance activities, from asset description to critical information discovery (DataHub, 2024).
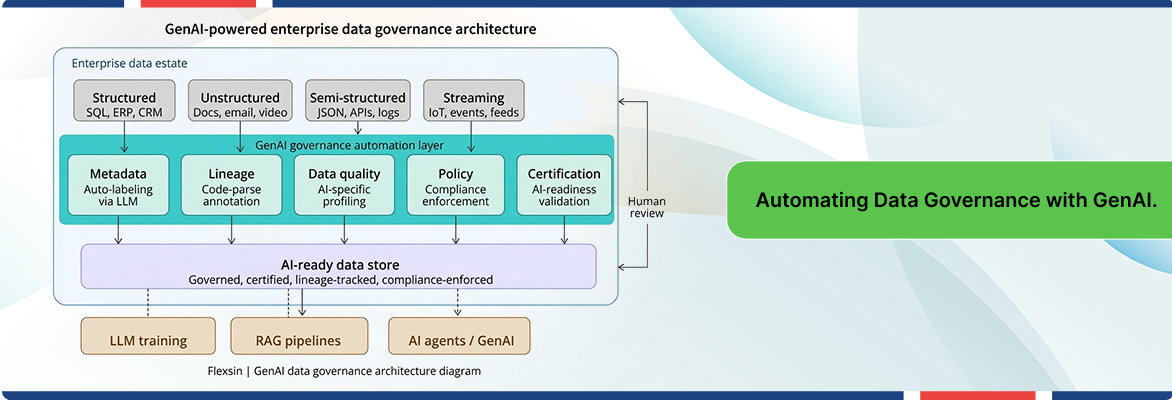
Why the Human-in-the-Loop Is Still Non-Negotiable
None of what is described above eliminates human governance expertise. The most effective GenAI data management architectures operate on a validate-don’t-create model: AI generates metadata drafts, lineage annotations, quality assessments, and compliance flags, and human stewards review, approve, and intervene on edge cases.
Our experience across large enterprise deployments is this: organizations that try to fully automate data governance for GenAI, without human checkpoints accumulate technical debt in their data catalogs faster than the AI can generate it. The ones that build intelligent human-AI collaboration models – using GenAI for scale and humans for judgment – build the only sustainable data infrastructure for AI.
People Also Ask:
What is GenAI for data management?GenAI for data management uses large language models to automate data governance tasks – including metadata labeling automation, lineage annotation, data quality profiling, and data compliance automation AI policy enforcement. It addresses the scale problem that unstructured data governance creates for traditional governance processes.
How does generative AI data quality differ from traditional data quality?Traditional data quality focuses on accuracy, completeness, and consistency. Generative AI data quality also evaluates representativeness, bias distribution, and AI-specific properties like near-duplicate contamination and training data alignment.
What is AI-ready data and why does it matter?AI-ready data is a dataset that has been validated for use in AI training or retrieval pipelines. It must be representative, governed, documented with automated metadata management, and compliant with applicable regulations – requirements that go well beyond traditional data readiness standards.
How much does poor data quality cost enterprises deploying GenAI?Industry research shows poor data quality costs organizations an average of $12.9 million annually. For GenAI specifically, Gartner projects 60% of AI projects will be abandoned by 2026 if they lack AI-ready data foundations.
What is data lineage automation in a GenAI context?Data lineage automation uses GenAI to generate and maintain cross-system traceability records for data assets. It replaces manual documentation with AI-generated lineage drafts that governance teams then validate, dramatically reducing the time required for audit-ready compliance.
Build an AI-Ready Data Foundation with Flexsin
Most GenAI deployments do not fail because of the model. They fail because the data underneath the model was never governed, never classified, and never made AI-ready. Flexsin’s Data Analytics and AI services help enterprises close that gap – building the automated metadata management, lineage, and data quality infrastructure that production-grade GenAI demands.
If your AI initiatives are stalling at proof of concept, the problem is almost certainly in the data layer. Flexsin brings the technical depth and enterprise delivery experience to assess your current data governance maturity, design the right human-AI stewardship model, and implement the automation layer that makes AI-ready data a repeatable operational outcome – not a one-time project.
Explore Flexsin’s Data Analytics and AI consulting services at https://www.flexsin.com/data-analytics/data-analytics-automation/ and start building the data governance layer your GenAI strategy requires.

Frequently Asked Questions:
1. What is the difference between AI data governance and traditional data governance? Traditional data governance was built for structured, database-resident data with relatively stable schemas. AI data governance must address unstructured data at massive scale, enforce AI-specific quality requirements, and track lineage across model training pipelines.
2. How long does it take to implement automated metadata management at enterprise scale?Implementation timelines vary by estate size and existing tooling, but organizations using modern AI data catalog platforms typically see initial automation running within eight to twelve weeks for a scoped data domain. Enterprise-wide rollout typically spans six to twelve months.
3. What tools support GenAI data governance frameworks?Enterprise-grade platforms include Collibra, Informatica, Alation, Atlan, and Microsoft Purview, each of which has integrated GenAI capabilities for automated cataloging, lineage mapping, and policy enforcement.
4. Is data lineage automation suitable for regulated industries?Yes – automated data lineage is particularly valuable in regulated industries such as financial services and healthcare, where audit trails are mandatory and the cost of manual documentation is prohibitively high.
5. How does a CDO build the business case for GenAI data governance investment?The most effective business case anchors to risk reduction and AI project ROI. With Gartner projecting 60% of AI projects will fail without AI-ready data foundations, and poor data quality costing organizations an average of $12.9 million annually.
